AWS Data Engineering Project
Data pipeline using AWS Glue ETL, S3, Athena and QuickSight
Outline
The goal of the project was to practise creating a data pipeline with Spotify data. The pipeline includes the use of AWS Glue, S3, and Athena. The architecture of this project is as follows:
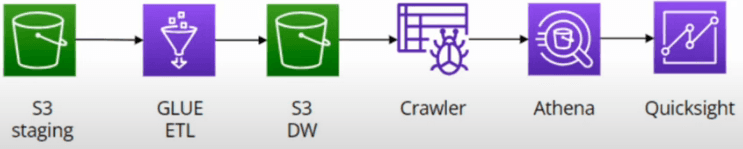
AWS Glue will be used to build the ETL pipeline and transfer the data to S3 data warehouse from staging. Our S3 bucket contains a staging folder where the data is extracted from Spotify and a datawarehouse folder where the data is loaded into. We can use the visual ETL tool to create the data pipeline. We provide it an IAM role to access glue and S3.

A glue crawler will be used to extract the data from S3 and load it into the data warehouse. It will populate a table in a database which we create prior to running the crawler. This database is stored in our S3 bucket inside the datawarehouse folder. AWS Athena will be used to query the data warehouse. AWS QuickSight can be used to visualize the data and provide business insights.
Technologies Used
AWS
AWS Glue
S3
Athena
SQL
Website
n/a
Github
n/a